Televisual Time
The following is a research report originally posted on the Mellon Fellow's website titled "Learning As We Go Along".
Digital humanities projects can be fickle beasts. Of course, any sort of research can be unpredictable. Progress often comes in fits and starts and the path forward is rarely clear. Unforeseen obstacles are part of game. But the application of digital methods to humanistic questions adds a twist. Digital tools have a life all their own and sometimes things don’t go as planned.
I encountered this personally when working with Dr. Joel Burges on his Televisual Time project. The aim of the project is to employ digital, distant reading techniques to TV Guide Magazine in order to discover how time is structured in and through televisual experience. Like many digital projects, the first step was to build a data set.
Two possibilities for building the data set presented themselves. The first was to transcribe the content by hand, an inconvenient and time-consuming prospect. Thus, since hand transcription wasn’t a live option, a second course was chosen. This involved scanning paper copies of TV Guide and employing Optical Character Recognition (OCR) technology to generate searchable text from the images.
Tracy Stuber, who preceeded me as research assistant for the TV Guide project, started the process. She scanned a selection of TV Guide issues and made some first attempts at running OCR software on the images.
But the task of generating a searchable text version of the scans proved surprisingly difficult. Tracy made the first attempt to run OCR software on the scans using the OCR built into Adobe Reader. But the results were mixed. Take for example, page 5 from the May 1-7 1953 edition.

Notice the layout of the page. The stylized title of the article, the multiple columns of text, the images laid out with captions. These visual features, while very familiar to the modern, human eye, proved to be only somewhat readable by a machine. Here is what Adobe’s OCR technology delivered when run on this page:
old favorites take heart because TED MACK’S BACK T ed mack’s triumphant return to television with his Original Amateur Hour, largely in answer to the demands of loyal viewers, has raised hopes of scores of other former favorites now absent from video screens. When Mack’s new show was scheduled for the NBC network, it touched off speculation that many other shows, formerly very popular, .were on the way back. In Mack’s case, thousands of letters,
There is a lot that worked well here. We have some strange artifacts like the hard break after “T” and the extra period added between “popular” and “were” in the third-to-last line, but the text is largely in good order. But notice that the image captions were completely omitted. The program didn’t even register these at all. A puzzling outcome, possibly due to the lay out of the captions. But this was a harbinger of things to come. For although the OCR seemed to work fairly well on articles like this one, the core of TV Guide Magazine is the schedule. And here things got worse. Take for example, this page from the same issue.

Here’s a close-up of the top of the page.
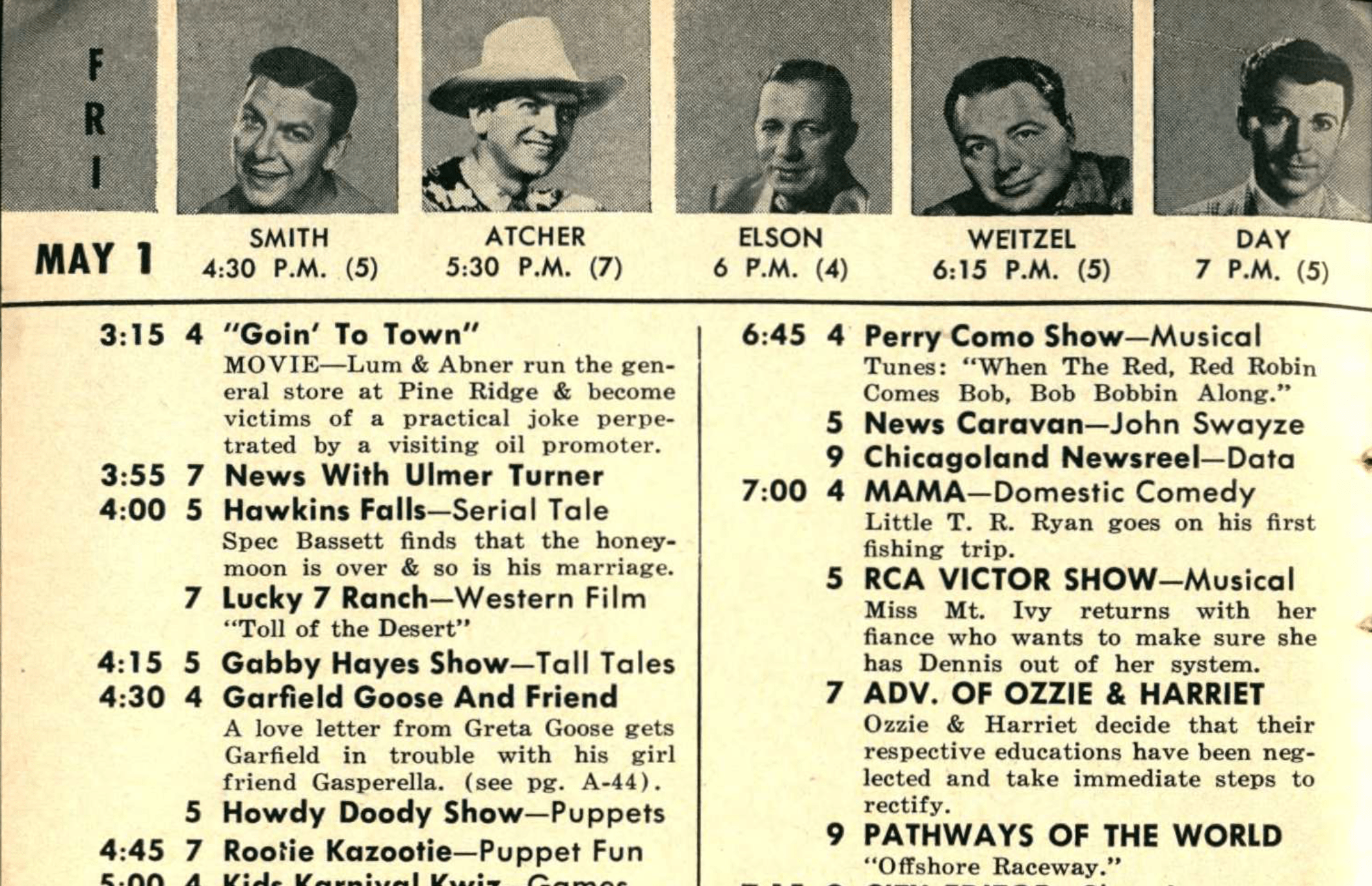
Note the elaborate visual structure. The top of the page includes captioned images to feature certain programs. The schedule itself is laid out in such a way as to make things easy to understand, but hard for a machine to process. For instance, we have a column indicating the time, a column indicating the channel, and a column listing the program with a description. But the times aren’t repeated for each show. And not every channel airs a program at every time. This visual structure is completely lost on the OCR technology. Here is an excerpt of the Adobe OCR of this page.
FR MAY 1 3:15 3:55 4:00 4:15 4:30 4:45 5:00 5:15 5:30 5:45 5:50 6:00 6:10 6:15 6:25 6:30 SMITH ATCHER ELSON WEITZEL DAY 4:30 P.M. (5) 5:30 P.M. (7) 6 P.M. (4) 6:15 P.M. (5) 7 P.M. (5) 4 "Goin' To Town" MOVIE—Lum & Abner run the general store at Pine Ridge & become victims of a practical joke perpetrated by a visiting oil promoter. 7 News With Ulmer Turner 5 Hawkins Falls—Serial Tale Spec Bassett finds that the honeymoon is over & so is his marriage. 7 Lucky 7 Ranch—Western Film “Toll of the Desert”
Obviously, we’ve got some problems. The OCR read the times as a separate column but still separated them with hard returns. This completely divorces the times from the listings. It then included the names from the featured programs at the top, this time reading them all as one line while the times associated are, once again, separated from their targets. Things go a bit better when we consider the text of the programs. Here, at least, we get the full sentences, with proper capitalization, and the associated channel listing. But this information doesn’t do much help without connecting listings with their times.
At this point, I attempted a switch in technologies. Google produced an application called Tesseract which is now open source. I was hopeful that Tesseract might be able to improve upon things. Alas, it was not to be. Here’s Tesseract’s output on the same passage. Forgive the length, I wanted to portray the output as it was when it was generated.
MAY I
3:I5
3:55
4:00
4:I5
4:30
5:15
5:30
5:45
5:50
6:00
6:10
6:I5
6:25
6:30
4:30 P.M. (5)
4
VIN
("8 00 NM‘NUI
UthlUIAVOVUlhul .Q Who N
7
9
SMITH
5:30 P.M. (7)
"Goin' To Town"
MOVIE—Lum & Abner run the gen-
eral store at Pine Ridge & become
victims of a practical joke perpe-
trated by a visiting oil promoter.
News With Ulmer Turner
Hawkins Falls—Serial Tale
Spec Bassett finds that the honey-
moon is over & so is his marriage.
lucky 7 Ranch—Western Film
“Toll of the Desert"
Here, we discover even more problems! And things only get worse when we run more recent issues through the OCR. Take this page from a 2001 edition of the magazine.

And here, in its entirety, is the text obtained from this page via one of the OCR runs:
SATURDAY 6:00AM-12:00PM AUGUST18 48 I TV GUIDE Oakland Rebuild (8044/03)
That’s it. Just two paltry lines. And literally none of the information from the grid was even registered as characters, let alone correctly. Other pages with a similar structure produced semi-readable results, but Tesseract didn’t see what the human eye sees: the grid structure. So the text read straight across the line without consideration for the lines dividing the cells.
All of this led me to the inevitable conclusion. Our data set was not going to be created via the OCR technologies in their present state. And, given how much time hand entering the data would take, the prospect of obtaining a usable data set for a distant reading approach seemed a pipe dream. So Dr. Burges declared the experiment over and moved on to a different research method. And I walked away having learned about the limitations of OCR technologies, the complexity of visually displayed data in print formats, and the way that DH projects have a life of their own.
Skills and Experience:
- Project ideation.
- Command line interface.
- Image processing with Imagemagick and Adobe products.
- Opitcal character recognition use and tuning with Adobe Acrobat and Tesseract.